patroni로 구현하는 PostgreSQL 고가용성

patroni로 구현하는 PostgreSQL 고가용성
들어가며
PostgreSQL 가용성을 높이는 방법은 단지 데이터베이스 차원에서만 구현 할 수 없다.
(가용성 = auto failover로 운영 DB 접속이 안될 때, 대기 서버가 운영 DB로 그 역할을 대신 하는 것 + 부하분산 - PostgreSQL은 읽기 전용 서버에 대해서만 부하분산이 가능하다)
(가용성 = auto failover로 운영 DB 접속이 안될 때, 대기 서버가 운영 DB로 그 역할을 대신 하는 것 + 부하분산 - PostgreSQL은 읽기 전용 서버에 대해서만 부하분산이 가능하다)
어떤 서비스의 가용성을 높이는 것은 결국 그 서비스를 제공하고 있는 호스트 문제와도 연결되며, 더 나아가 그 호스트와 연결되어있는 네트워크 장비와도 연결되어있다.
그래서, PostgreSQL 개발 그룹에서는 이 가용성 문제는 데이터베이스 영역을 벗어나기 때문에 다루지는 않는다.
지금까지도 그렇다.
이 가용성 문제를 푸는 가장 보편적인 방법은 OS 클러스터링 솔루션을 이용하는 것이다.
오픈소스로 대표적인 것은 Pacemaker이다. 하지만, pacemaker 구축과 관리 비용이 상당히 비싸다. (배우기 어렵다.)
여러개의 읽기 전용 복제 서버를 만들고, 그것들을 이용해서 읽기 전용 작업에 대한 부하 분산을 하는 것은 오래전부터 표준화 되었기 때문에 따로 언급하지는 않겠지만,
읽기-쓰기 인스턴스(Primary, Master, Leader 같은 용어로 지칭한다.)의 auto failover, 더 나아가 편한 switchover (안정적인 상태에서 다른 호스트로 읽기-쓰기 인스턴스를 옮기는 일) 기능을 제공하는 것에는 아직까지는 표준화 된 것이 없다.
전통적인 방법으로는 공유 디스크를 이용해서 Active 호스트가 문제가 있을 때, Standby 호스트가 Active 호스트에서 사용하던 데이터베이스 자료 디스크를 마운트해서 데이터베이스 인스턴스를 실행하는 방법이 이용되었다.
이 방법은 failover, switchover 작업 비용이 거의 없다.
해당 공유 디스크가 물리적으로 문제만 없다면, 자료 손실도 없다.
하지만, IT 인프라 환경이 클라우드 기반으로 옮겨가고, 이 공유 디스크를 사용할 수 없는 환경에서 failover 문제를 풀어야 한다면, 물리적인 스트리밍 복제 기능을 이용해서 읽기 전용 인스턴스를 읽기-쓰기 인스턴스로 바꿔 그것을 운영 디비로 쓰는 방식을 사용할 수 밖에 없다.
이 글은 이부분에 관한 이야기다.
patroni 프로그램이 auto failover와 switchover를 담당하고, 그 내부 작업에 대해서는 운영자가 신경을 최대한 안쓰게 하기 위함이다.
또한 OS 클러스터 솔루션과 달리 네트워크 환경, OS 환경은 전혀 고려하지 않고, 데이터베이스 서비스에만 집중에서 auto failover를 구현한다.
(그래서, pacemaker 구축 보다 쉽다.)
이 이야기의 시작은 EnterpriseDB사에서 소개하고 있는 patroni 이야기다.
해당 글은
https://www.enterprisedb.com/docs/supported-open-source/patroni/rhel8_quick_start/
페이지에서 읽을 수 있다.
구성도
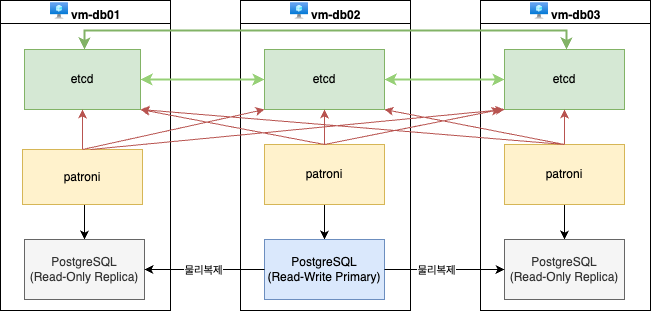
(draw.io 이용)
필요한 것들
- Rocky Linux 8 Virtual Machine 3대 (쌍방간 네트워크 가능한 상태)
- 각 호스트는 hostname -s 값으로 서로 통신 가능해야함 /etc/hosts 있든 dns에 등록되든
- etcd : https://etcd.io/
- patroni : https://github.com/patroni/patroni
- postgresql : https://postgresql.org/
etcd
https://download.postgresql.org/pub/repos/yum/common/pgdg-rhel8-extras/redhat/
에서 해당 플랫폼에 맞게 rpm 파일을 받아서 그냥 설치했다.
다른 패키지 의존성이 전혀 없는 프로그램이기 때문에, 서비스 설정 관련을 편하게 하기 위해서 rpm 파일을 이용했다.
patroni
python 가상환경에서 pip으로 설치했다.
patroni 부터는 postgres 계정에서 전적으로 관리하기 때문에,
OS root와 관계 없이 실행될 수 있도록 했다.
root 권한으로 필요한 것은 python3 패키지를 설치하는 것 뿐.
su - postgres mkdir patroni cd patroni python3 -m venv . pip install patroni[etcd,psycopg3]
pip install 작업이 성공하려면, pip build 작업을 할 수 있는 각종 개발 패키지들이 필요하다.
작업 과정에서 오류 메시지를 잘 읽어보고 몇번의 시행착오만 거치면 쉽게 마칠 수 있다.
pip 명령을 사용할 수 없는 패쇄망 환경이라면,
인터넷 망에서 윗 작업을 하고,
/home/postgres/patroni 디렉토리만 패쇄망으로 옮겨 같은 위치에서 사용하면 될 것이다.
PostgreSQL
설치 관련해서는 설명 생략.
etcd 구성
etcd 프로그램은 key-value 멀티마스터 데이터베이스다.
최소 3대로 묶여야 클러스터링 환경에서 그들 간의 auto failover를 진행하기 때문에,
번거롭지만 각 호스트 마다 설치를 하고, 설정하고, 하나의 클러스터로 묶는다.
이 데이터베이스에는 patroni에서 사용하는 각종 PostgreSQL 클러스터링 정보를 저장한다.
방화벽 포트
이러기 위해서는 당연히 각 호스트에서 etcd가 사용하는 포트가 열려있어야한다.
OS 방화벽이나, 기타 네트워크 방화벽 설정이 되어있다면, 사전에 2379, 2380 포트 통신이 가능한 상태로 만들어야 한다.
(이런 작업을 해야할 상황이라면, 추가로 patroni가 쓰는 8008, postgresql이 쓰는 5432 포트도 함께 여는 작업도 한다.)
etcd 서비스 설정
클러스터로 묶어둔 etcd 세트가 망가지면,
patroni가 postgresql 클러스터 재구성 작업을 하다가 실패하면서 멀쩡히 잘 쓰고 있는 PostgreSQL 인스턴스가 중지될 수 있다.
그래서, etcd 프로그램은 OS 서비스로 등록하고, 중지되면 무조건 재실행한다는 설정까지 필요하다.
운영환경에서는 최악의 경우라도 두개의 etcd 인스턴스는 정상 실행되어 클러스터링 되고, patroni가 etcd를 통해서 postgresql 클러스터 정보를 받을 수 있도록 운영 되어야 한다.
rpm파일로 설치하고 나면
/usr/lib/systemd/system/etcd.service 파일에서 Restart 설정을 always로 바꾼다.
Restart=always
다음 서비스 변경분을 반영하고, etcd 서비스를 활성화 한다.
systemctl daemon-reload && systemctl enable etcd
다음 /etc/etcd/etcd.conf 파일을 다음과 같이 만든다.
#[Member] # LISTEN 관련 설정은 포트 바인딩 이기 때문에 반드시 IP로 지정되어야 한다. ETCD_LISTEN_PEER_URLS="http://172.30.1.161:2380" ETCD_LISTEN_CLIENT_URLS="http://localhost:2379,http://172.30.1.161:2379" ETCD_NAME="vm1" #[Clustering] #여기서부터는 바인딩과 관계없는 호스트 정보들임으로 호스트 이름으로 설정해도 괜찮다. ETCD_INITIAL_ADVERTISE_PEER_URLS="http://vm1:2380" ETCD_INITIAL_CLUSTER="vm1=http://vm1:2380,vm2=http://vm2:2380,vm3=http://vm3:2380" ETCD_ADVERTISE_CLIENT_URLS="http://vm1:2379" ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster-1" ETCD_INITIAL_CLUSTER_STATE="new"
IP 주소는 모두 적당히 바꿔야 한다.
위의 예제는 vm1의 경우이기 때문에, vm1이라는 글자와, 172.30.1.161 IP 주소가 사용되었다.
vm2, vm3 도 적당히 알맞게 바꿔야 한다.
ETCD_INITIAL_CLUSTER 설정은 세 호스트 모두 같다. 규칙은 etcd 인스턴스이름(ETCD_NAME)과 해당 IP로 구성된다.
준비가 다 되었으면, 세 호스트 모두 etcd 서비스를 실행한다.
systemctl start etcd
이렇게 3 호스트 모두 etcd 설정을 마치고 서비스를 시작했다면,
etcdctl member list 명령 결과로 3 줄 목록이 나와야한다.
ETCD_INITIAL_CLUSTER 에서 지정한 각 호스트들이다.
root@vm1:~# etcdctl member list 7b6a22d036981d50, started, vm2, http://172.30.1.162:2380, http://vm2:2379, false a2cb95237c4b2bf3, started, vm1, http://172.30.1.161:2380, http://vm1:2379, false a9cfb614665e6b05, started, vm3, http://172.30.1.163:2380, http://vm3:2379, false
watchdog 설정
patroni 에서 /dev/watchdog 장치를 사용하면 좀 더 OS 장애 상황을 빠르게 파악한다고 해서 설정하기를 권장한다.
이 부분은 EnterpriseDB사에서 소개하고 있는 글을 그대로 따랐다.
kernel 모듈을 로딩하고, 파일 소유주를 바꾸는 작업을 OS차원에서 자동화하는 작업이다.
[root@vm1 ~]# cat /etc/udev/rules.d/99-watchdog.rules KERNEL=="watchdog", OWNER="postgres", GROUP="postgres" [root@vm4 ~]# cat /etc/modules-load.d/softdog.conf softdog
최종 모습은 OS가 리부팅 되고 난 뒤에도 항상
ls -l /dev/watchdog crw-rw----. 1 postgres postgres 10, 130 1월 28 13:41 /dev/watchdog
이런 모습이어야 한다.
patroni 실행
postroni 프로그램은 postgresql 인스턴스를 자기 상황에 알맞게 primary 인스턴스로 실행할 것인지, 읽기 전용 복제 인스턴스로 실행할 것인지를 판단해서 postgresql 인스턴스를 실행하는 프로그램이다.
또한 postgresql 인스턴스를 모니터링 하고 있다가 해당 인스턴스가 문제가 생기면 etcd 쪽으로 인스턴스 상황을 보고해서, auto failover (다른 복제 인스턴스가 promote 작업을 해서 주서버(primary server)로 변경하는 일)을 하는 것이 주 목적이다.
또한 자신이 관리하는 postgresql을 새롭게 실행해야 하는 상황에서 복제 서버로 실행되어야 하는 경우 - 이미 주서버가 잘 작동되고 있는 상황 - pg_rewind 명령을 이용해서 최대한 빠르게 복제 서버를 구축해서 실행하는 일도 한다.
즉, patroni 프로그램을 사용하게 되면,
DB 인스턴스는 pg_ctl 명령이 아니라,
patroni 명령을 실행해서 그 프로그램이 DB 인스턴스를 성격에 알맞게 실행하게 하고,
patronictl 명령으로 DB인스턴스의 모니터링과 관리자가 임의로 각 인스턴스를 자격 변경을 하게된다.
patroni, patronictl 명령을 사용하기 위해서는,
이 글과 같은 구성 환경에서는 postgres 계정 대상으로
몇가지 OS 환경 변수 설정과 patroni 환경 구성 파일을 미리 지정해야 한다.
이 작업은 3 호스트 모두 해야 하며, 각 호스트에 맞게 설정을 바꿔야 한다.
다른 클러스링 도구들과 달리 설정을 각각 해야 하는 것이 조금은 성가시다.
(etcd도, patroni도 다 각 호스트에 맞게 설정해야 한다.)
.bash_profile 내용
export PGDATA=/data/demo export PATH=/postgres/16/bin:$PATH export PATRONICTL_CONFIG_FILE=/home/postgres/patroni.yml . $HOME/patroni/bin/activate
윗 설정에서 지정했듯이, /home/postgres/patroni.yml 파일은 다음과 같다.
patroni.yml 내용
scope: demo-cluster #클러스터이름
namespace: /db/
name: vm1 #인스턴스 노드 이름(호스트이름과 동일)
# patroni 내부 각종 정보 조회및 조작 서버 설정 각 호스트별로 자신의 호스트를 사용한다.
restapi:
listen: "0.0.0.0:8008"
connect_address: "172.30.1.161:8008"
authentication:
username: patroni
password: mySupeSecretPassword
# etcd 클러스터로 묶여 있는 모든 호스트 정보를 나열
# (호스트 이름이 ip로 바뀔 수 있는 경우는 아래처럼 호스트 이름으로
# 그렇지 않으면, 각 IP 주소로 지정)
etcd3:
hosts:
- vm1:2379
- vm2:2379
- vm3:2379
# postgresql 인스턴스를 실행하려고 했는데, 해당 인스턴스가 전혀 준비가 안된 상태라면
# 아에 처음부터 시작하는데, 그 설정
bootstrap:
dcs:
ttl: 30
loop_wait: 10
retry_timeout: 10
maximum_lag_on_failover: 1048576
postgresql:
use_pg_rewind: true
use_slots: true
parameters:
archive_mode: "on"
archive_command: "/bin/true"
initdb:
- encoding: UTF8
- lc-collate: C
- lc-ctype: ko_KR.utf8
- data-checksums
- auth-local: peer
- auth-host: scram-sha-256
pg_hba:
- host replication replicator 0.0.0.0/0 scram-sha-256
- host all all 0.0.0.0/0 scram-sha-256
# PostgreSQL 실행할 때의 환경 설정
postgresql:
listen: "0.0.0.0:5432"
connect_address: "172.30.1.161:5432"
data_dir: /data/demo
bin_dir: /postgres/16/bin
bin_name:
postgres: /postgres/16/bin/postgres
pgpass: /home/postgres/patroni-pgpass
authentication:
replication:
username: replicator
password: confidential
superuser:
username: postgres
password: my-super-password
rewind:
username: rewind_user
password: rewind_password
parameters:
unix_socket_directories: "/tmp"
timezone: "Asia/Seoul"
log_timezone: "Asia/Seoul"
patroni.member: "vm1"
# 추가로 가상 IP 설정을 테스트 하기위해 임의 스크립트를 추가했음
callbacks:
on_role_change: "/home/postgres/on_role_change.sh"
watchdog:
mode: required
device: /dev/watchdog
safety_margin: 5
tags:
nofailover: false
noloadbalance: false
clonefrom: false
nosync: false
patroni 프로그램을 실행할 때는 해당 설정 파일을 지정해야한다.
patroni patroni.yml > patroni.log 2>&1 &
이 작업을 OS가 부팅 되고 난 뒤에 자동으로 실행되기를 원한다면,
patroni 실행 작업을 서비스로 등록해 두면 된다.
(각 OS에서 사용자 정의 서비스 등록에 대한 이야기는 여기서는 생략한다.)
patroni는 Pacemaker 같은 OS 클러스터 관리 도구가 아니다!
오직 PostgreSQL 인스턴스 관리에만 촛점이 맞춰있어,
Virtual IP를 주서버(Primary Server) 기준으로 설정하고,
failover가 발생하면, 가상 IP를 바꾸고 하는 것은 patroni 기본 기능이 아니다.
그래서, OS 관리자와 DB 관리자가 분리되어 있는 운영 환경이라면,
patroni 관련 운영은 DB 관리자가 전적으로 맡는 것이 좋을 것이다.
여기서는 이 정책에 맞춰, 실행도, 모니터링도, 로그 분석도 postgres 계정으로 모두 할 수 있도록 구성했다.
patronictl 과 모니터링
데이터베이스 인스턴스는 두 대만 있어도 되지만,
etcd 서비스를 어차피 3 대로 하기에 vm1, vm2, vm3 모두 같은 환경의 데이터베이스를 운영하는 것으로 테스트했다.
또한 아래에서도 이야기하지만,
auto failover 나 switchover 가 끝난 뒤, 옛날 주서버를 새로운 주서버의 리플리카를 만드는 사이에 또 failover 나 switchover가 일어날 경우 예상치 못한 클러스터 전면 재구축 작업을 해야하는 불상사를 막기 위함이기도 하다.
트랜잭션 로그를 스트리밍 기법으로 전달하고, 그것을 복제 인스턴스에서 그대로 반복 반영해서 복제 인스턴스를 관리하는 기법은 이 주서버와 복제 서버간 동기화 기법이 비동기식(async)인 경우는 운영환경에서는 두 대의 복제 인스턴스를 두는 것이 안전한 것 같다.
(동기식 복제라면 복제 서버가 하나여도 최악의 사태는 막을 수 있을 것 같다. 이 부분은 테스트를 해보질 못했다.)
모든 작업이 끝나면, patronictl 명령으로 클러스터 상태를 살펴본다.
(patroni) postgres@vm1:~$ patronictl list + Cluster: demo-cluster (7464125923163850844) ---+-----------+ | Member | Host | Role | State | TL | Lag in MB | +--------+--------------+---------+-----------+----+-----------+ | vm1 | 172.30.1.161 | Replica | streaming | 84 | 0 | | vm2 | 172.30.1.162 | Leader | running | 84 | | | vm3 | 172.30.1.163 | Replica | streaming | 84 | 0 | +--------+--------------+---------+-----------+----+-----------+
Replica들은 모두 상태가 'streaming' 상태여야하고, Leader는 'running' 상태여야한다.
이런 상황이 아니면 비정상 상태다.
리플리카가 'running' 상태로 계속 되고 있는 경우는
- 완전 재초기화가 필요해서 아주 오랫동안 리플리카를 구축하고 있거나,
- 스트리밍 복제 쪽에 문제가 있는 상황이다.
스트리밍 복제 문제가 있는 경우는 가장 손쉽게 푸는 방법은 해당 member 를 patronictl reinit 명령으로 재초기화하는 것이다.
모니터링은 이것이 전부다.
문제는 이런 스트리밍 복제 쪽에 문제가 생긴 상황을 방치해 두면, PostgreSQL 스트리밍 복제 환경에서 발생하는 다양한 문제를 그대로 직면하게 될 수 있다.
예를 들어, 위 list 결과로 3개의 인스턴스가 나오고, 리플리카가 2 인스턴스라면, 주서버에는 2개의 복제 슬롯이 만들어진다.
윗 예제 기준으로 vm3 호스트를 아에 shutdown 해서 더이상 사용하지 않는다고 했을 때,
patronictl list 에서 vm3 관련 정보가 사라질 때까지 vm3 관련 복제 슬롯은 주서버에서 사라지지 않는다. (정말 중요한 이야기다!)
앞에서 이야기했듯이, 리플리카인데, streaming 상태를 유지하지 않는 것이 보인다면 최대한 빠른 시간 안에 해당 문제를 풀어야한다. 그렇지 않으면, 복제 슬롯 때문에 트랜잭션 로그 적체가 일어나고, 주서버 인스턴스쪽 디스크 공간 관리에 문제가 발생할 수 있다.
아무 생각 없이 그냥 방치 해 둔다고 알아서 모든 상황을 patroni가 클러스터 각 DB 인스턴스들을 잘 관리하는 것은 아니다!
patronictl reinit
(patroni) postgres@vm2:~$ patronictl topology + Cluster: demo-cluster (7464125923163850844) ----------+ | Member | Host | Role | State | TL | Lag in MB | +--------+------+---------+-----------+-----+-----------+ | vm3 | vm3 | Leader | running | 169 | | | + vm1 | vm1 | Replica | streaming | 169 | 0 | | + vm2 | vm2 | Replica | running | 169 | 16 | +--------+------+---------+-----------+-----+-----------+
patroni가 관리하는 클러스터의 해당 인스턴스 계층 구조를 본 화면이다.
앞에서 설명한 Replica 인스턴스인데, streaming 상태가 아닌 vm2 인스턴스가 발견되었다.
vm2 인스턴스가 리플리카로 정상적으로 실행되고 있지 못하는 상태를 뜻한다.
vm2 인스턴스를 로그를 보면,
2025-02-01 22:07:26.554 KST [727] LOG: started streaming WAL from primary at 0/9D000000 on timeline 169 2025-02-01 22:07:26.554 KST [727] FATAL: could not receive data from WAL stream: ERROR: requested WAL segment 000000A9000000000000009D has already been removed 2025-02-01 22:07:26.554 KST [515] LOG: waiting for WAL to become available at 0/9D0002E8
이런 로그가 계속 찍히고 있다. 물리 복제 오류 메시지 가운데 흔히 보는 메시지다.
주서버에 000000A9000000000000009D 트랜잭션 로그 조각 파일이 이미 지워져 버려 vm2 리플리카를 못하고 있는 상황이다.
이때 이것을 방치하면, vm3(주서버)의 vm2용 복제 슬롯이 활성화 되어 있기 때문에, vm3 쪽에서 자료 변경 작업이 계속 일어난다면, vm3의 pg_wal 디렉터리의 여유 공간은 점점 줄어들게 될 것이다.
해결 방법은
- vm2의 patroni 프로세스를 중지해서 아에 vm2 인스턴스를 사용하지 않거나,
- vm2 인스턴스를 새로 만들어야 한다.
새로 만들 때 사용하는 명령이 reinit 명령이다.
(patroni) postgres@vm2:~$ patronictl reinit --help Usage: patronictl reinit [OPTIONS] CLUSTER_NAME [MEMBER_NAMES]... Reinitialize cluster member Options: --group INTEGER Citus group --force Do not ask for confirmation at any point --wait Wait until reinitialization completes --help Show this message and exit. (patroni) postgres@vm2:~$ patronictl reinit --wait demo-cluster vm2 + Cluster: demo-cluster (7464125923163850844) ----------+ | Member | Host | Role | State | TL | Lag in MB | +--------+------+---------+-----------+-----+-----------+ | vm1 | vm1 | Replica | streaming | 169 | 0 | | vm2 | vm2 | Replica | running | 169 | 16 | | vm3 | vm3 | Leader | running | 169 | | +--------+------+---------+-----------+-----+-----------+ Are you sure you want to reinitialize members vm2? [y/N]: y Success: reinitialize for member vm2 Waiting for reinitialize to complete on: vm2 Reinitialize is completed on: vm2 (patroni) postgres@vm2:~$ patronictl topology + Cluster: demo-cluster (7464125923163850844) ----------+ | Member | Host | Role | State | TL | Lag in MB | +--------+------+---------+-----------+-----+-----------+ | vm3 | vm3 | Leader | running | 169 | | | + vm1 | vm1 | Replica | streaming | 169 | 0 | | + vm2 | vm2 | Replica | streaming | 169 | 0 | +--------+------+---------+-----------+-----+-----------+
테스트
failover 관련 테스트는 전통적으로 failover가 자동으로 발생되어야 하는 모든 가능성을 테스트하는 것이다.
앞에서 이야기했듯이 이 failover는 전통적인 OS 클러스터 솔루션이 담당했던 Virtual IP 전환에 대한 부분은 빠져있다.
- 호스트가 power off 되었을 때
- 호스트가 멈췄을 때, hang on 또는 stuck 이라고는 하는 현상
- 호스트의 과부화
- etcd 데몬 프로세스 문제
- patroni 데몬 프로세스 문제
- postgres 데몬 프로세스 문제
- 네트워크 인터페이스 down
- ...
이런 식으로 모든 가능성을 나열하고 하나씩 테스트 한다.
지금까지 테스트 한 것으로는 etcd 클러스터가 망가졌을 때가 가장 치명적이다.
최악의 사태를 대비해서 etcd 자료 백업 복구 연습을 충분히 두어야 할 것 같다.
failover를 고려한 클라이언트
자동 failover는 서비스 연속성 분야에서 아주 중요한 부분이다.
virtual ip나, haproxy 나, pgbouncer, pgpool 같은 추가 도구나 설정 없이, etcd + patroni 만으로 서비스 연속성을 보장하려면, 이 postgresql 데이터베이스를 쓰는 클라이언트에서 추가 작업이 필요하다.
libpq 기반 클라이언트들
psql이나, pg_dump, 같은 기본 PostgreSQL 클라이언트 도구들이이나, python 프로그래밍에서 사용하는 psycopg 라이브러리를 사용하는 클라이언트들을 말한다.
여기서는 데이터베이스 서버 연결 문자열을 사용할때, target_session_attrs=read-write 설정을 추가하면 지정한 여러 인스턴스 가운데, 주서버로 자동으로 접속하는 기능을 제공한다.
(patroni) postgres@vm1:~$ psql "host=vm1,vm2,vm3 target_session_attrs=read-write" postgres=# show patroni.member; patroni.member ---------------- vm3 (1개 행)
윗 설정은 항상 read-write 인스턴스로만 접속하는 것이고, 반대로 read-only (윗 경우라면, vm1, vm2) 인스턴스를 임의로 선택해서 접속하려면, target_session_attrs=read-only load_balance_hosts=random 설정을 추가하면 된다.
서비스 연속성 테스트
테이블 하나 만들기
postgres=# \d t
"public.t" 테이블
필드명 | 형태 | 정렬규칙 | NULL허용 | 초기값
--------+-----------------------------+----------+----------+------------------------------
a | timestamp without time zone | | |
b | integer | | not null | nextval('t_b_seq'::regclass)
c | text | | |
인덱스들:
"t_pkey" PRIMARY KEY, btree (b)read-write 연속성 테스트
1초 간격으로 계속 insert 작업하기
(patroni) postgres@vm1:~/test$ cat psql_insert.sh
while true
do
psql "host=vm1,vm2,vm3 target_session_attrs=read-write" \
-c "insert into t values (current_timestamp, default, current_setting('patroni.member')) returning *"
sleep 1
done
(patroni) postgres@vm1:~/test$ sh psql_insert.sh
a | b | c
----------------------------+------+-----
2025-01-28 18:09:34.206879 | 6780 | vm2
(1개 행)
INSERT 0 1
a | b | c
----------------------------+------+-----
2025-01-28 18:09:35.263846 | 6781 | vm2
(1개 행)
INSERT 0 1이렇게 계속 insert 작업을 하고 있는 중에 다른 호스트에서 patronictl switchover 작업을 진행한다.
(patroni) postgres@vm3:~$ patronictl switchover demo-cluster --candidate vm1 --scheduled now --leader vm2 --force Current cluster topology + Cluster: demo-cluster (7464125923163850844) ---+-----------+ | Member | Host | Role | State | TL | Lag in MB | +--------+--------------+---------+-----------+----+-----------+ | vm1 | 172.30.1.161 | Replica | streaming | 94 | 0 | | vm2 | 172.30.1.162 | Leader | running | 94 | | | vm3 | 172.30.1.163 | Replica | streaming | 94 | 0 | +--------+--------------+---------+-----------+----+-----------+ 2025-01-28 18:13:19.63234 Successfully switched over to "vm1" + Cluster: demo-cluster (7464125923163850844) -+-----------+ | Member | Host | Role | State | TL | Lag in MB | +--------+--------------+---------+---------+----+-----------+ | vm1 | 172.30.1.161 | Leader | running | 94 | | | vm2 | 172.30.1.162 | Replica | stopped | | unknown | | vm3 | 172.30.1.163 | Replica | running | 94 | 0 | +--------+--------------+---------+---------+----+-----------+
정상적으로 vm1으로 switchover 가 될 때, psql_insert.sh 실행 결과를 살펴본다.
a | b | c
----------------------------+------+-----
2025-01-28 18:13:16.026525 | 6844 | vm2
(1개 행)
INSERT 0 1
a | b | c
----------------------------+------+-----
2025-01-28 18:13:17.079092 | 6845 | vm2
(1개 행)
INSERT 0 1
psql: 오류: "vm1" (172.30.1.161), 5432 포트로 서버 접속 할 수 없음: 세션이 읽기 전용임
"vm2" (172.30.1.162), 5432 포트로 서버 접속 할 수 없음: 연결이 거부됨
해당 호스트에 서버가 실행 중이고, TCP/IP 접속을 허용하는지 확인하세요.
"vm3" (172.30.1.163), 5432 포트로 서버 접속 할 수 없음: 세션이 읽기 전용임
psql: 오류: "vm1" (172.30.1.161), 5432 포트로 서버 접속 할 수 없음: 세션이 읽기 전용임
"vm2" (172.30.1.162), 5432 포트로 서버 접속 할 수 없음: 연결이 거부됨
해당 호스트에 서버가 실행 중이고, TCP/IP 접속을 허용하는지 확인하세요.
"vm3" (172.30.1.163), 5432 포트로 서버 접속 할 수 없음: 세션이 읽기 전용임
a | b | c
----------------------------+------+-----
2025-01-28 18:13:20.170898 | 6848 | vm1
(1개 행)
INSERT 0 1
a | b | c
----------------------------+------+-----
2025-01-28 18:13:21.196725 | 6849 | vm1
(1개 행)
INSERT 0 1
a | b | c
----------------------------+------+-----
2025-01-28 18:13:22.239153 | 6850 | vm1
(1개 행)
INSERT 0 13초 걸렸다. vm2 에서 vm1으로 잘 넘어갔다. (내 목구멍으로 소주 한잔도 잘 넘어갔다.)
여기까지 테스트는
- 데이터베이스 작업을 하기 전에 데이터베이스로 접속을 하고,
- 작업 SQL을 실행하고,
- 데이터베이스 연결을 끊는 작업을
반복한 것인데, 이런 반복 작업은 운영환경에서는 거의 일어나지 않는다.
대부분의 반복작업은
- 처음 한 번 데이터베이스로 연결하고,
- SQL 작업을 반복하고,
- 연결을 끊는 방식을
사용한다.
아쉽게도 psql 에서는 이 부분을 지원하지 않는다.
psql reconnection 기능을 제공하기는 하지만, 다중 호스트, target_session_attrs=read-write 설정을 고려해서 잘 작동하지는 않는다. (개선되면 좋을 듯)
그래서, python psycopg 모듈을 이용한 간단한 테스트 스크립트를 만들어서 테스트 해 보았다.
(추가로 pip install psycopg-pool 도 필요하다.)
(추가로 pip install psycopg-pool 도 필요하다.)
(patroni) postgres@vm1:~/test$ cat conn_pool.py
import psycopg
import psycopg_pool
import time
dsn ="host=vm1,vm2,vm3 target_session_attrs=read-write connect_timeout=5"
pool = psycopg_pool.ConnectionPool(conninfo=dsn)
def myconnect():
while True:
try:
conn = pool.getconn()
if not conn.closed:
return conn
break
except Exception as e:
print(e)
time.sleep(1)
conn = myconnect()
while True:
try:
cur = conn.cursor()
cur.execute("insert into t values (current_timestamp, default, current_setting('patroni.member')) "\
"returning *,pg_backend_pid()")
conn.commit()
row = cur.fetchone()
cur.close()
print(row[0], row[1], row[2], row[3])
time.sleep(1)
except Exception as e:
print("error!")
cur.close()
conn.close()
pool.close()
pool = psycopg_pool.ConnectionPool(conninfo=dsn)
conn = myconnect()
time.sleep(1)
(patroni) postgres@vm1:~/test$ python conn_pool.py
2025-01-28 18:39:07.348516 6963 vm3 1205
2025-01-28 18:39:08.357589 6964 vm3 1205
2025-01-28 18:39:09.367712 6965 vm3 1205마지막 1205는 해당 세션의 backend 프로세스 pid이다. 같다면, 그 세션이 끊기지 않고 작업하고 있음을 의미한다.
여기서도 patroni switchover 테스트를 해 보면,
2025-01-28 18:44:02.586864 7030 vm3 1214 2025-01-28 18:44:03.598007 7031 vm3 1214 2025-01-28 18:44:04.608094 7032 vm3 1214 error! error connecting in 'pool-2': connection failed: connection to server at "172.30.1.163", port 5432 failed: FATAL: the database system is shutting down error connecting in 'pool-2': connection failed: connection to server at "172.30.1.163", port 5432 failed: FATAL: the database system is shutting down error connecting in 'pool-2': connection failed: connection to server at "172.30.1.163", port 5432 failed: FATAL: the database system is shutting down error connecting in 'pool-2': connection failed: connection to server at "172.30.1.163", port 5432 failed: FATAL: the database system is shutting down error connecting in 'pool-2': connection failed: connection to server at "172.30.1.163", port 5432 failed: server closed the connection unexpectedly This probably means the server terminated abnormally before or while processing the request. error connecting in 'pool-2': connection failed: connection to server at "172.30.1.163", port 5432 failed: server closed the connection unexpectedly This probably means the server terminated abnormally before or while processing the request. error connecting in 'pool-2': connection failed: connection to server at "172.30.1.163", port 5432 failed: server closed the connection unexpectedly This probably means the server terminated abnormally before or while processing the request. error connecting in 'pool-2': connection failed: connection to server at "172.30.1.163", port 5432 failed: server closed the connection unexpectedly This probably means the server terminated abnormally before or while processing the request. 2025-01-28 18:44:09.438773 7065 vm1 2124 2025-01-28 18:44:10.450736 7066 vm1 2124 2025-01-28 18:44:11.461425 7067 vm1 2124
잘 넘어가고 잘 작동했다.
patroni를 이용한 auto failover 기능을 사용하고, 기타 다른 proxy 소프트웨어를 사용하지 않겠다면, 데이터베이스 접속 문자열 설정을 잘 해야하는 것과,
해당 접속이 끊겼을 때, 다시 재접속하는 작업을 응용 프로그램에서 반드시 구현해야 한다.
실재 pool는 미리 몇개의 연결을 해 놓고, 그것 가운데 하나를 가져와서 DB 쿼리를 하고, 쿼리가 끝나면 그 연결을 풀러에게 반환하는 방식을 사용하기 때문에, 이 부분도 윗 코드를 조금 바꿔 다시 테스트 해 봤다.
(patroni) postgres@vm1:~/test$ cat conn_pool2.py
import psycopg
import psycopg_pool
import time
dsn ="host=vm1,vm2,vm3 target_session_attrs=read-write connect_timeout=5"
pool = psycopg_pool.ConnectionPool(conninfo=dsn)
while True:
with pool.connection() as conn:
try:
with conn.execute("insert into t values (current_timestamp, default, current_setting('patroni.member')) "\
"returning *,pg_backend_pid()") as cur:
conn.commit()
row = cur.fetchone()
print(row[0], row[1], row[2], row[3])
time.sleep(1)
except Exception as e:
print(e)
time.sleep(0.1)
(patroni) postgres@vm1:~/test$ python conn_pool2.py
2025-02-01 18:23:11.585164 9405 vm3 637
2025-02-01 18:23:12.594700 9406 vm3 636
2025-02-01 18:23:13.607007 9407 vm3 638
2025-02-01 18:23:14.621884 9408 vm3 639
2025-02-01 18:23:15.631616 9409 vm3 637
2025-02-01 18:23:16.643578 9410 vm3 636
2025-02-01 18:23:17.653505 9411 vm3 638
2025-02-01 18:23:18.664466 9412 vm3 639
terminating connection due to administrator command
discarding closed connection:
terminating connection due to administrator command
error connecting in 'pool-1': connection failed: connection to server at "172.30.1.163", port 5432 failed: server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
discarding closed connection:
terminating connection due to administrator command
error connecting in 'pool-1': connection failed: connection to server at "172.30.1.163", port 5432 failed: server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
discarding closed connection:
terminating connection due to administrator command
error connecting in 'pool-1': connection failed: connection to server at "172.30.1.163", port 5432 failed: server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
discarding closed connection:
error connecting in 'pool-1': connection failed: connection to server at "172.30.1.163", port 5432 failed: server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
2025-02-01 18:23:20.804151 9439 vm2 1319
2025-02-01 18:23:21.813625 9440 vm2 1320
2025-02-01 18:23:22.833537 9441 vm2 1321
2025-02-01 18:23:23.844478 9442 vm2 1322
2025-02-01 18:23:24.860096 9443 vm2 1319 vm3의 637..639 백엔드 세션을 쓰고 반복해서 쓰고 있다가 vm2의 1319..1322 세션으로 잘 넘어갔다. 2초 걸렸다.
여기서 haproxy 를 이용한 접속 정보 고정 하는 부분을 다루지 않는 것은 결국 haproxy에 대한 고가용성도 또 고려해야하기 때문이다.
jdbc 기반 클라이언트들
jdbc 에서는 단순히 connection url 설정에 대해서만 언급한다.
read-write 호스트로 자동 접속하는 옵션:
jdbc:postgresql://vm1,vm2,vm3/dbname?targetServerType=primary
read-only 호스트들 가운데 임의 접속하는 옵션:
jdbc:postgresql://vm1,vm2,vm3/dbname?targetServerType=secondary&loadBalanceHosts=true
failover, switchover 와 응용 프로그램의 pooler 문제
기억해야 할 사실은,
읽기-쓰기 인스턴스가 읽기전용 인스턴스로 바뀔 때는 인스턴스가 재실행 되기 때문에, 연결 되어 있던 모든 클라이언트의 backend 세션들이 모두 정리가 된다.
이에 맞춰 응용 프로그램을 위에서 소개한 것처럼 연결이 끊기게 되면 재접속을 하는 예외처리가 되어있다면, 별 문제 없이 연결이 정리가 된다.
문제는,
읽기전용 인스턴스가 읽기-쓰기 인스턴스로 바뀔 때에는 그 인스턴스가 재실행되지 않는다.
그래서, 읽기전용 인스턴스 상태에 연결 되어 있던 클라이언트들의 backend 세션들이 정리가 되질 않는다.
아주 낙천적으로 생각하면, 어차피 idle timeout 설정 때문에 언젠가는 다 끊어지겠지 생각할 수도 있겠지만, 읽기 전용 인스턴스의 부하가 심한 상태였다면, 운영상 치명적인 문제가 될 수도 있을 것이다.
읽기전용 인스턴드들의 부하 분산과 그 인스턴스를 사용하고 있는 응용 프로그램이 pooler를 사용하고 있는 환경이라면, 좀 더 고민을 해 봐야할 문제로 보인다.
(아직 답을 못 찾았다. ChatGPT는 Spring Boot 인경우는 사용자 정의 데이터소스 라우팅 기법으로 해결 하라고 한다. 아무튼 이 영역(읽기전용 인스턴스들이 여럿 있고, 응용 프로그램은 pooler를 쓰는 경우에 구현하는 부하분산)은 응용 프로그램을 왕창 고치든, haproxy 같은 부하분산를 처리하는 인스턴스가 있어야 할 것 같다. )
Virtual IP 설정
이 부분은 일반적인 네트워크 환경에서는
PostgreSQL 공식 빌드 저장소 가운데, extra 저장소를 이용해서,
vip-manager 패키지를 이용하면 손쉽게 설정할 수 있다.
아래 글은 이 사실을 모르고 혼자서 삽질한 결과물이다.
그냥 기록 삼아 남겨둔다.
vip-manager 사용법에 대해서는
https://github.com/cybertec-postgresql/vip-manager
페이지 참조.
-------
OS 클러스터 솔루션을 사용하지 않고, etcd + patroni 만으로 클러스터 대표 IP 주소를 지정하고, 응용 프로그램이 그 대표 IP를 사용해서 서비스 하는 것에 대한 고민이였는데,
결론은 앞에서 계속 다루웠듯이 클러스터 소속 모든 IP를 응용프로그램에서 지정하고,
데이터베이스 접속을 담당하는 라이브러리가 알아서 원하는 데이터베이스로 접속하도록 하는 것이 제일 안전한 방법인 듯하다.
하지만, 윗 patroni.yml 파일에서 테스트 하려고 설정했던 on_role_change.sh 스크립트가 있으니, 이것을 테스트한 기록도 남긴다.
virtaul ip 로 윗 환경에서는 172.30.1.170 으로 정했다.
그리고 on_role_change.sh 스크립트에서
이 virtual ip 할당 작업을 한다.
스크립트 내용은 다음과 같다.
(patroni) [postgres@vm4 ~]$ cat on_role_change.sh #!/bin/sh VIRTUALIP="172.30.1.170" ETHDEV="enp0s1" GATEWAY="172.30.1.254" CLUSTERNM=`curl -s http://localhost:8008 | jq -r .patroni.scope` sudo ifconfig $ETHDEV:1 down sudo arp -d $VIRTUALIP PGPRIMARY=`etcdctl get --print-value-only=true /db/$CLUSTERNM/leader` MYHOSTNAME=`hostname -s` if [ "$PGPRIMARY" = "$MYHOSTNAME" ]; then sudo ifconfig $ETHDEV:1 $VIRTUALIP/24 # debian 계열 OS에서는 아래 -s 옵션을 -S 로 바꿔야 한다. sudo arping -c 3 -w 5 -I $ETHDEV -U $GATEWAY -s $VIRTUALIP fi
이 스크립트가 실행이 되면 (해당 patroni 에서 역할이 바뀌기 시작하면 - primary 에서 standby 가 되든가, standby 에서 primary로 바뀌든가 -)
먼저 vip가 할당된 이더넷 인터페이스를 down하고,
해당 vip를 arp 캐시에서 지우고,
etcd 를 통해 leader가 누군지 찾고, (이때, patroni.yml 에서 지정한 namespace와 scope 설정을 지정한다. /db/demo-cluster/)
leader와 자신이 같으면, vip 설정하고,
arping 명령으로 vip의 mac 주소가 바뀌었음을 알린다.
ifconfig, arp 작업들은 모두 root 작업이기 때문에,
sudo 명령으로 진행하며 sudoers 설정도 필요하다.
vip 바꾸기 작업을 이렇게 하면 어떻게든 되기는 한다.
그런데 많이 번거롭다.
(patroni 구축 자체가 많이 번거롭기는 하다.)
----------------
하나 더.
위와 같은 이더넷 장치에 별칭 IP를 추가하는 것으로 VIP를 구현해도 복잡한 클라우드 가상 네트워크 환경인 경우에는 문제가 안풀리는 경우가 있다.
이때는 iptables의 포트 포워딩을 이용해서, primary 인스턴스에 대해서만 5432 포트가 열리는 식으로 설정하고, (가상화 되어있든 말든) L4 장비에 이 DB인스턴스들의 호스트와 5432 포트를 지정해 auto failover를 구현할 수 있을 것이다.
이렇게 하기 위해서는 먼저 모든 데이터베이스의 서비스 포트를 다른 포트(6432)로 바꿔 설정을 하고, 위 on_role_change.sh 스크립트에서 iptables 설정을 하는 방식도 있을 것이다.
#!/bin/sh CLUSTERNM=`curl -s http://localhost:8008 | jq -r .patroni.scope` # 일단 5432 포트 포워딩 설정을 지우고, sudo iptables -D PREROUTING -t nat -i enp0s1 -p tcp --dport 5432 -j REDIRECT --to-port 6432 PGPRIMARY=`etcdctl get --print-value-only=true /db/$CLUSTERNM/leader` MYHOSTNAME=`hostname -s` if [ "$PGPRIMARY" = "$MYHOSTNAME" ]; then # 내가 포트 포워딩을 해야 하는 경우면 설정을 추가하고. sudo iptables -A PREROUTING -t nat -i enp0s1 -p tcp --dport 5432 -j REDIRECT --to-port 6432 fi
이정도면, 일단 데이터베이스 인스턴스 측에서는 할 것은 다했다.
------
이랬는데, patroni 에서 이 문제를 미리 알고,
/primary API를 제공하고 있었다.
http://vm1:8008/primay
호출했을 때 HTTP header 응답 코드가 200이면 primary 다.
그렇지 않은 500을 던진다.
즉, L4 설정에서 DB 인스턴스 health check 를 이걸로 하면 된다.
L4 그룹에 모든 DB 인스턴스를 등록하고, 각 인스턴스가 사용가능한지를 검사하는 것은
윗 8008 웹서버의 /primary 페이지를 호출해서 검사하는 식으로 구성하면 된다.
나머지는 L4에게 맡긴다.
------
응용프로그램을 수정할 수 없는 상황으로 데이터베이스 접속 IP 주소를 하나 밖에 지정할 수 없다면, 부득이 이렇게 vip 설정을 할 수는 있겠지만,
이런 저런 테스트를 해본 결과 데이터베이스 운영하는 입장에서는
위에서 언급한 것 처럼 응용프로그램에서 데이터베이스 연결하는 방식을
다중 호스트 지정를 지정하고, 그 가운데 primary를 찾아서 접속하라고 하고,
작업 도중 접속이 끊어지면, 다시 접속하는 예외처리를 포함 해서 응용프로그램을 구현하는 것이 제일 좋을 듯하다.
마치며
- 운영환경에서는 당연히 postgres.yml 파일 내용을 좀 더 섬세하게 설정할 필요가 있다.
- etcd 클러스터링 문제 상황에 대한 대처 능력이 필요하다. (백업, 복구)
- 각 소프트웨어 업그레이드나 패치에 대한 안정적인 운영 지침이 필요하다.
- 기존 단일 postgresql 서비스를 이 etcd + patroni + postgres 구성으로 구축하는 방법도 준비해야 할 것
- psycopg_pool 모듈에서 DB 다중 읽기 전용 인스턴스의 부하분산된 pooling 구현 해킹도 필요하다.
올해 설 명절 긴 연휴, 이렇게 신나게 놀고 있다.