PostgreSQL이 사용하는 대표 Scan과 그 Cost
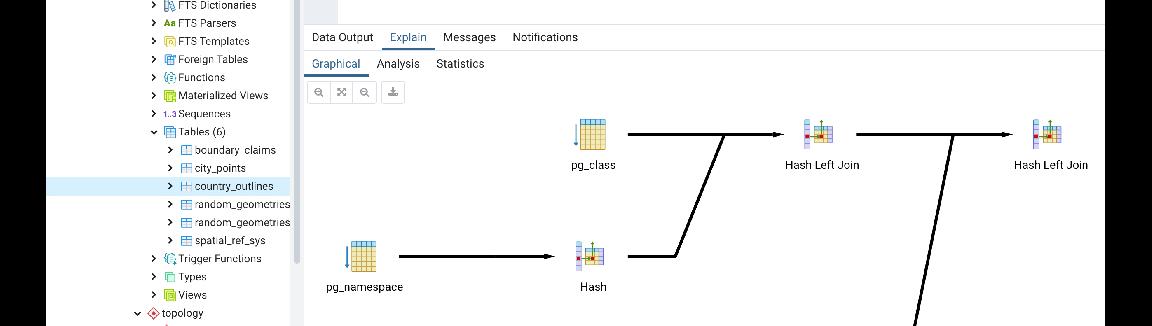
PostgreSQL이 사용하는 대표 Scan과 그 Cost
explain 명령으로 쿼리 실행 계획을 보면 각 세부 작업으로 어떤 것을 한다는 식으로 그 단계에서 진행되는 작업을 설명하고 있습니다.
그 작업 설명은 크게 Scan, Join, Sort, Aggregate, ...... 등 쿼리의 각 요소들이 하는 일입니다.
이 글은 저 작업들 가운데 가장 많이 보이는 Scan과 그 가운데 대표적인 Scan들의 작업비용을 실행계획기는 어떻게 추측하는가에 대한 이야기입니다.
explain 명령 결과로 보이는 Scan들
PostgreSQL explain 명령 결과는 읽고 이해하기가 많이 힘듭니다.
특히 psql 같은 텍스트 기반 툴에서는 거의 암호문 수준입니다.
처음 접하는 사람은 대부분 당혹감을 감출 수 없습니다.
이 글의 대표 사진은 그나마 explain을 시각화 하는데 비교적 충실한 pgAdmin으로 출력한
explain select * from pg_tables 명령 결과입니다.
해당 작업을 psql에서 하면 다음과 같이 보입니다.
# explain select * from pg_tables where tablename = 'pg_class';
QUERY PLAN
----------------------------------------------------------------------------------------------------------
Nested Loop Left Join (cost=0.27..10.43 rows=1 width=260)
Join Filter: (t.oid = c.reltablespace)
-> Nested Loop Left Join (cost=0.27..9.38 rows=1 width=140)
Join Filter: (n.oid = c.relnamespace)
-> Index Scan using pg_class_relname_nsp_index on pg_class c (cost=0.27..8.29 rows=1 width=80)
Index Cond: (relname = 'pg_class'::name)
Filter: (relkind = ANY ('{r,p}'::"char"[]))
-> Seq Scan on pg_namespace n (cost=0.00..1.04 rows=4 width=68)
-> Seq Scan on pg_tablespace t (cost=0.00..1.02 rows=2 width=68)여기서 'Index Scan', 'Seq Scan' 이렇게 보이는 것들에는 어떤 종류가 있는지 살펴보기 위해 소스 코드를 뒤졌습니다.
src/backend/commands/explain.c 에 있더군요.
다음은 PostgreSQL에서 다루는 Scan 종류입니다.
- Seq Scan : 힙 순차 검색
- Sample Scan : tablesample 절이 있을 때
- Index Scan : 인덱스로 찾아 힙 자료를 출력할 때
- Index Only Scan : 인덱스 만으로 자료를 출력할 때
- Bitmap Index Scan : 인덱스 찾기 결과를 비트맵으로 만들고
- Bitmap Heap Scan : 만들어진 비트맵을 힙 ctid랑 비트맵 연산으로 자료를 뽑을 때
- Tid Scan : where ctid = .... 일때
- Tid Range Scan : where ctiid between ... 일때
- Subquery Scan : 서브쿼리과 관계된 scan
- Function Scan : 집합 반환 함수 사용 때
- Table Function Scan : 테이블 반환 함수 사용 때
- Values Scan : 말그대로
- CTE Scan : 말그대로
- Named Tuplestore Scan : 아직 안 찾아봤고
- WorkTable Scan : 아직 안 찾아봤고
- Foreign Scan : 외부 테이블 참조 때
- Custom Scan : 아에 모르겠고
이들 중 가장 많이 사용되고, 기초가 되는 것은 Seq, Index, Bitmap Index & Bitmap Heap Scan 정도입니다. 이 글은 이들 설명과 explain 에서 보이는 그 cost를 설명해 볼까 합니다.
explain의 cost
explain 명령은 해당 쿼리를 실행할 때, 각 세부 실행 계획 (일반적인 용어로 쿼리 스탭이라고 합니다.) 의 순서를 보여줍니다. 이 순서는 실행계획기가 여러가지 조건으로 총 비용을 계산해서 가장 싼 비용이 드는 순서입니다. 이 비용이 말 그대로 cost라고 하며,
이 비용의 기준이 되는 것이 '데이터 페이지 (8kb씩 나눠진 테이블의 한 영역 - 흔히 다른 관계형 데이터페이스에서는 이것을 데이터 블록이라고 합니다.) 하나를 디스크에서 메모리로 가져오는 작업을 1이라고 하자.' 라는 것입니다.
그리고 이 cost 계산을 위한 데이터베이스 환경 설정 매개 변수를 쭉 지정합니다.
# select name,setting from pg_settings where name like '%cost';
name | setting
-------------------------+---------
cpu_index_tuple_cost | 0.005
cpu_operator_cost | 0.0025
cpu_tuple_cost | 0.01
jit_above_cost | 100000
jit_inline_above_cost | 500000
jit_optimize_above_cost | 500000
parallel_setup_cost | 1000
parallel_tuple_cost | 0.1
random_page_cost | 4
seq_page_cost | 1pg_settings에서 cost로 끝나는 것을 찾으면 이렇습니다.
지면 관계상, short_desc 칼럼은 생략했습니다. 이 칼럼을 포함면 각 변수들의 설명을 간단하게 읽을 수 있습니다.
맨 밑에 있는 seq_page_cost가 바로 앞에서 설명한 그것입니다.
윗 값은 PostgreSQL 기본값입니다.
아주 간단합니다.
인덱스를 사용해서 자료를 찾고, 그 실 자료가 있는 테이블에서 자료를 뽑는(random_page_cost) 는 seq_page_cost보다 4배 비싸다.
인덱스를 사용해서 자료를 찾고, 그 실 자료가 있는 테이블에서 자료를 뽑는(random_page_cost) 는 seq_page_cost보다 4배 비싸다.
메모리에 가져온 데이터페이지에서 자료를 하나 처리하는 작업(cpu_tuple_cost)는 1/100 정도 싸다.
이런 식입니다.
Seq Scan 테이블 전체 순차 탐색
이것은 테이블 또는 구체화된 뷰를 그냥 처음부터 끝까지 쭉 읽는 것을 뜻합니다.
즉 cost는 해당 객체의 페이지수가 될 것입니다.
경우는 두가지겠죠.
- 하나는 조회 조건을 보니, 인덱스를 사용할 수 없는 경우이거나,
- 자료량이 많지 않아 데이터 페이지가 네 개보다 작아서 인덱스를 사용하면 비용이 더 드는 경우.
(여기서 주의해야할 것은 실행계획기는 그 테이블의 실제 페이지가 몇개인지를 직접 계산하지 않고, pg_class.relpages 값으로 판단합니다. 그런데, 이 값은 테이블 통계 정보가 수집되기 전까지는 마지막 수집했을 때의 값이고, 한번도 통계 수집 작업이 일어나지 않았다면, 0 입니다. 0인 경우는 내부적으로 기본 비용 계산으로 진행해서 실행계획을 만들어버립니다. 즉, 자료가 갑자기 많이 변경된 경우라면, 그것도 용량이 큰 테이블이라면, 통계 수집기가 그 변경분을 반영하기 전까지는 엉뚱한 실행계획을 짤 가능성이 있다는 것을 기억해야합니다. 통계수집기가 사라진 15버전에서는 어떤 상황이 벌어질지 아직 경험해 보지는 못했습니다.)
실세계 자료라면 대부분 테이블은 인덱스를 사용하면 비용이 더 들 정도로 자료량이 많지 않은 경우는 잘 없습니다. 그래서, 쿼리 튜닝을 할 때 제일 먼저 살펴보는 부분은 인덱스를 사용 사용하는 것이 좋은데, 이 테이블 전체 순차 탐색을 하고 있는 부분이 있는지를 살펴보는 것입니다.
-- 먼저 pg_class 테이블의 통계 정보를 수집합니다.
ioseph=# analyze pg_class;
ANALYZE
ioseph=# select relpages from pg_class where relname = 'pg_class';
relpages
----------
14
(1개 행)
-- pg_class 테이블은 총 14 페이지입니다.
-- 이제 테이블 전체 순차 탐색을 하도록 인덱스 탐색과 비트맵 탐색을 사용하지 않겠다고 설정합니다.
ioseph=# set enable_indexscan = off;
SET
ioseph=# set enable_bitmapscan = off;
SET
-- 실행 계획을 봅니다.
ioseph=# explain select * from pg_class where relname = 'pg_class';
QUERY PLAN
-----------------------------------------------------------
Seq Scan on pg_class (cost=0.00..19.19 rows=1 width=265)
Filter: (relname = 'pg_class'::name)
(2개 행)pg_class 라는 테이블에서 relname 칼럼 값이 'pg_class'인 자료를 보여달라고 했을 때, 실행 계획기는 테이블 전체 순차 탐색을 할 것이고, 이 계획을 짠 근거는 총 비용이 19.19이기 때문이다고 합니다.
그리고 이 쿼리의 결과는 자료가 하나 나올 것이다(rows=1)고 예측하고, 그 출력 자료의 크기는 265 바이트일 것이다(width=265) 라고 예측했습니다.
저 19.19 는
# select (reltuples * 0.01) + (reltuples * 0.0025) + (relpages * 1) from pg_class where relname = 'pg_class'; ?column? ---------- 19.1875
입니다.
0.01 과, 0.0025, 1 상수 값은 이 글 위에서 찾아보세요.
Index Scan 인덱스를 이용한 임의 힙 페이지 탐색
드디어 힙 페이지라는 생소한 단어가 나옵니다. 별거 없습니다. 이 글에서 이야기한 테이블의 데이터 페이지로 이해하면 됩니다.
즉, 인덱스 탐색은 인덱스 객체도 검색하고, 그 테이블의 데이터 페이지도 읽는 작업을 말합니다.
PostgreSQL에서 다루는 자료는 가장 저수준으로 ctid라는 단위로 처리됩니다. 다른 RDBMS처럼 인스턴스 전체를 통틀어 이 자료의 고유 식별값이 없습니다.
즉, 어느 데이터베이스에 어느 테이블에 ctid.
이렇게 처리되어야 고유 식별값이 됩니다.
이 ctid 값이 인덱스의 key-value 관점에서 value가 됩니다.
즉 PostgreSQL 에서 사용하는 일반적인 인덱스(btree 인덱스 - 정확하게는 b+tree입니다)는 '이 자료는 테이블의 어느 페이지의 몇 번째 자료다' 라는 정보를 따로 모아둔 것입니다.
인덱스 내부는 pageinspect 라는 확장 모듈로 살펴 볼 수 있습니다.
-- pageinspect 확장 모듈을 설치합니다.
ioseph=# create extension pageinspect ;
CREATE EXTENSION
-- pg_class 테이블은 어떤 인덱스를 사용하는지 살펴봤습니다.
ioseph=# \d pg_class
"pg_catalog.pg_class" 테이블
필드명 | 형태 | 정렬규칙 | NULL허용 | 초기값
---------------------+--------------+----------+----------+--------
oid | oid | | not null |
relname | name | | not null |
relnamespace | oid | | not null |
relfrozenxid | xid | | not null |
......
relminmxid | xid | | not null |
relacl | aclitem[] | | |
reloptions | text[] | C | |
relpartbound | pg_node_tree | C | |
인덱스들:
"pg_class_oid_index" PRIMARY KEY, btree (oid)
"pg_class_relname_nsp_index" UNIQUE CONSTRAINT, btree (relname, relnamespace)
"pg_class_tblspc_relfilenode_index" btree (reltablespace, relfilenode)
-- 릴레이션 이름에 대한 인덱스가 pg_class_relname_nsp_index 인 것을 보고,
-- 이 인덱스의 두번째 페이지에는 어떤 자료가 들어있는지 살펴봅니다.
-- (인덱스의 첫번째 페이지는 테이블의 페이지와 달리 인덱스 그 자체에 대한 정보가 담겨 있어 자료가 없습니다.
ioseph=# select itemoffset, htid,
convert_from(
decode(
replace(substr(data, 1, position(' 00' in data)), ' ' , ''),
'hex'),
'utf8') from bt_page_items('pg_class_relname_nsp_index', 1) limit 10;
itemoffset | htid | convert_from
------------+---------+-----------------------------------
1 | | pg_range
2 | (10,8) | _pg_foreign_data_wrappers
3 | (10,11) | _pg_foreign_servers
4 | (10,5) | _pg_foreign_table_columns
5 | (10,14) | _pg_foreign_tables
6 | (10,17) | _pg_user_mappings
7 | (4,25) | a
8 | (8,19) | administrable_role_authorizations
9 | (8,18) | applicable_roles
10 | (8,21) | attributes
(10개 행)첫번째 자료는 다음 페이지는 'pg_range' 에서 시작한다는 다음 페이지 힌트고 실 자료는 릴레이션 이름이 '_pg_foreign_data_wrappers' 인 자료는 pg_class 테이블의 10번 페이지 8번째 자료다고 알려줍니다.
즉, select * from pg_class where relname = '_pg_foreign_data_wrappers' 이렇게 쿼리한다면,
pg_class_relname_nsp_index 인덱스에서 key가 '_pg_foreign_data_wrappers' 인 htid (힙테이블ID)를 구해서, 드디어 임의 페이지 접근(random page)을 해서 거기서 8번째 자료를 보여줍니다.
즉, 인덱스 탐색은 아무리 최소로 진행한다고 해도,
- 이 인덱스가 어떤 인덱스인지 알아야 하고, (인덱스 객체의 첫번째 블록은 읽어야하고)
- 그 인덱스에서 원하는 자료를 찾아야하고, (루트 - 브랜치 - 리프)
- 그래서 찾은 테이블의 블록을 읽어야 합니다.
그래서 random_page_cost를 4 정도로 하는 것이 기본값입니다.
다음은 pg_class 테이블에서 relname이 pg_class인 자료를 찾는 쿼리의 실행 계획입니다.
--이제 인덱스 탐색을 할 수 있도록 설정을 바꿉니다.
ioseph=# set enable_indexscan = on;
SET
ioseph=# explain select * from pg_class where relname = 'pg_class';
QUERY PLAN
---------------------------------------------------------------------------------------------
Index Scan using pg_class_relname_nsp_index on pg_class (cost=0.27..8.29 rows=1 width=265)
Index Cond: (relname = 'pg_class'::name)예상 했던 대로 pg_class_relname_nsp_index 라는 인덱스를 사용해서 인덱스 탐색을 하겠다고 알려줍니다. 그 비용은 총 8.29, 자료는 한개, 그 한 자료의 크기는 265바이트.
인덱스를 사용하지 않았다가, 인덱스를 사용하면,
전체 비용은 19.19에서 8.29로 거의 반 정도 비용이 싸진다고 실행계획기는 예측합니다.
(random_page_cost 값을 세배로 늘린다면, 실행 계획기는 seq scan을 선택하겠죠. 이런 식입니다.)
이 인덱스 탐색은 기억해야 하는 것이, 인덱스로 해당 자료의 tid를 찾으면 바로 그곳으로 가서 원하는 자료를 준비한다는 것입니다. 그래서, order by 를 지정하지 않아도 그 인덱스의 순서대로 자료가 출력됩니다.
즉, between 연산 처럼 여러 자료를 뽑을 경우라면, 여러 데이터 페이지를 왔다 갔다 하면서 읽었던 페이지를 또 읽는 일이 벌어집니다. 이런 비용도 줄여보고자 등장한 것이 비트맴 스캔입니다.
Bitmap Scan 비트맵을 이용한 탐색
PostgreSQL의 아주 독특한 탐색 방법입니다.
일단 인덱스를 탐색하면서 조건에 맞는 자료는 1, 아닌 것은 0 이렇게 페이지 단위 비트맵을 만들고(Bitmap Index Scan),
이 비트맵과 테이블의 각 페이지 tid 정보가 담긴 부분과 AND 연산을 한 결과를 뽑아 그 실 자료를 뽑는(Bitmap Heap Scan) 방식입니다.
테이블의 실 자료의 정렬도가 낮은데 (시계열 자료가 아니라는 말이죠), 그 칼럼 기준으로 검색은 해야겠는데, 굳이 인덱스 탐색(인덱스와 테이블 페이지를 왔다 갔다 하는 일)을 안해도 될 어느 정도(?)의 총 자료량이여서 쿼리 중에 임시로 메모리에 비트맵을 만들어될 만큼의 자료라고 예측 되면 이 비트맴 스캔을 실행계획기가 선택합니다.
(글이 너무 어렵네요. 아직도 정확하게 글 쓴 사람도 제대로 이해하지 못했다는 것입니다. - 사기는 말 많음에서 시작합니다. 음...)
아무튼 다 만들어진 비트맵 기준으로 데이터 페이지와 비교하기 때문에, 자료 결과는 데이터 페이지 순서로 자료가 나오게 됩니다.
다음은 index scan 과, bitmap scan 실행 계획 모습입니다.
ioseph=# explain select relname,relpages from pg_class where relname >= 'pg_a' and relname < 'pg_aa';
QUERY PLAN
--------------------------------------------------------------------------------------------
Index Scan using pg_class_relname_nsp_index on pg_class (cost=0.27..8.29 rows=1 width=68)
Index Cond: ((relname >= 'pg_a'::name) AND (relname < 'pg_aa'::name))
(2개 행)
-- 윗 쿼리를 비트맵 스캔으로 유도하려면, 임시로 인덱스 스캔을 사용하지 않는다고 설정합니다.
-- 그러면, 비트맵 스캔을 선택하던가 시퀀스 스캔을 선택하겠죠.
ioseph=# set enable_indexscan = off;
SET
ioseph=# explain select relname,relpages from pg_class where relname >= 'pg_a' and relname < 'pg_aa';
QUERY PLAN
-----------------------------------------------------------------------------------------
Bitmap Heap Scan on pg_class (cost=4.28..8.30 rows=1 width=68)
Recheck Cond: ((relname >= 'pg_a'::name) AND (relname < 'pg_aa'::name))
-> Bitmap Index Scan on pg_class_relname_nsp_index (cost=0.00..4.28 rows=1 width=0)
Index Cond: ((relname >= 'pg_a'::name) AND (relname < 'pg_aa'::name))
(4개 행) 이렇게 0.01 차이로 왔다갔다합니다.
마치며
관계형 데이터베이스의 실행계획 비용 계산 영역은 정말 어렵습니다.
게다가 이 실행계획을 결정하는 각종 환경 변수 값의 기본값은 2023년을 살아가고 있는 지금에는 현실적이지 않는 부분이 있습니다.
random_page_cost가 정말 seq_page_cost의 네 배나 될까? 라고 하면, 고속 비휘발성 메모리( NVMe - Non-Volatile Memory Express)를 주 저장장치로 쓰는 환경에서는 현실적인 값이 아님이 분명합니다.
아무튼 어설프게나마 PostgreSQL 실행계획에서 Scan 관련해서 살펴보면서 그 실행계획을 짜는데 기준이 되는 비용에 대해서 살펴봤습니다.